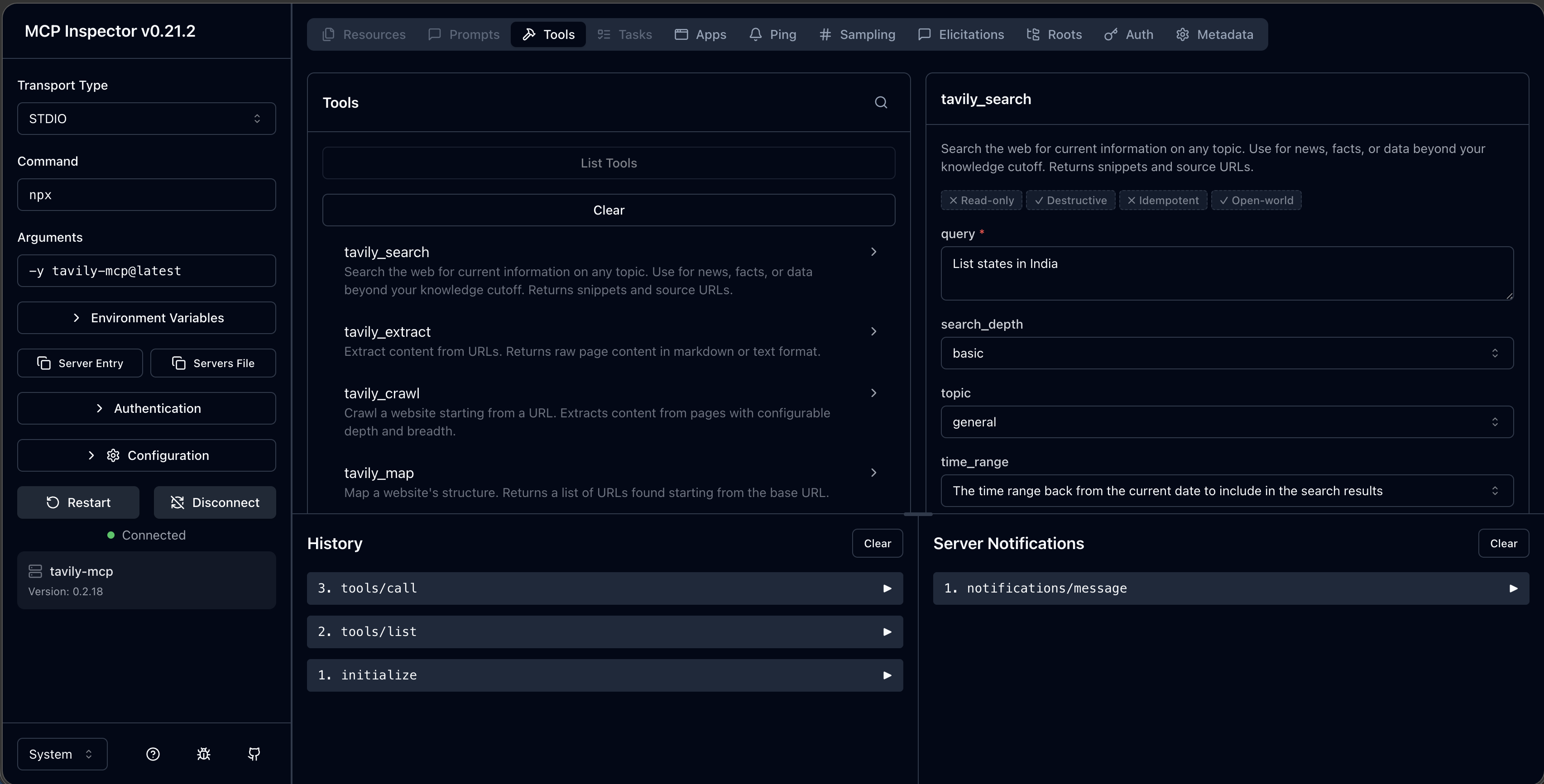
MCP Client/Server architecture
Developing tools that LLM agents can use is time-consuming and inconsistencies in implementation make them difficult to reuse. Anthropic introduced MCP to bring a transformation to the LLM tool integration. MCP establishes a common language for LLM agents to communicate with tools.
MCP consists of three component architecture: Host, Client and Server.
The Host is the application that interacts with users and make decisions using a LLM. It receives user input, performs reasoning, and decides which tools touse and when. Think of it as the "brain" of the system.
The MCP client acts as a bridge between the Host and MCP servers. When the Host decides it needs a tool, the client handles the communication, requesting available tool definitions from servers and forwarding tool execution requests. Each client maintain one connection to the MCP server.
The MCP server hosts the actual tools and executes them on demand. It responds what type of tools you have and execute this tool with these arguments. Servers can connects to the external resources such as databases and APIs.
flowchart TD
Host["Host Process<br/>Orchestrates"]:::host
Host -->|Creates and manages| C1
Host -->|Creates and manages| C2
Host -->|Creates and manages| C3
subgraph clients["Client Instances"]
direction LR
C1["Client 1"]
C2["Client 2"]
C3["Client 3"]
end
C1 -->|1:1| S1
C2 -->|1:1| S2
C3 -->|1:1| S3
subgraph servers["MCP Servers"]
direction LR
S1["File Server<br/>Resources: Files"]
S2["Database Server<br/>Tools: Queries"]
S3["API Server<br/>Prompts: Templates"]
end
classDef host fill:#3FB1F2,stroke:#2A9BD8,color:#fffTransport Mechanism
MCP supports three transport mechanism for communication between clients and servers.
-
stdio (Standard I/O)is the simplest approach. The client launches the server as a subprocesses and communicates through the standard input/output streams. Since everything runs locally on the same machine, there is no network overhead. This is ideal for local development. -
Streamable HTTPenables communicates over the network. The client sends the requests via HTTP and server streams responses back. -
Websocketprovides full bidirectional communication allowing both client and server to initiate messages. This is useful when servers need to push updates to clients proactively.
Standardized Interfaces
MCP standardized two key interfaces Tool Discovery and Tool Execution
Tool Discovery: The client request available tool definitions, and the server returns them in a standardized format. The tool developers implement the schema once and any MCP compatible client can automatically retrieve and use itTool Execution: The client sends a tool execution to the server which handles execution and returns the result in a consistent format.
MCP Primitives
Toolsare server exposed functions that clients invoke. Server define a tool with name, description and input schema. Example, read_file, query_database, fetch_apiResourcesare data sources or URIs. Server exposes file:// or custom:// URIs. It is static or dynamic.Promptsare reusable templates for LLM interactions. Servers define prompt templates with arguments. Client call get prompt function with arguments.